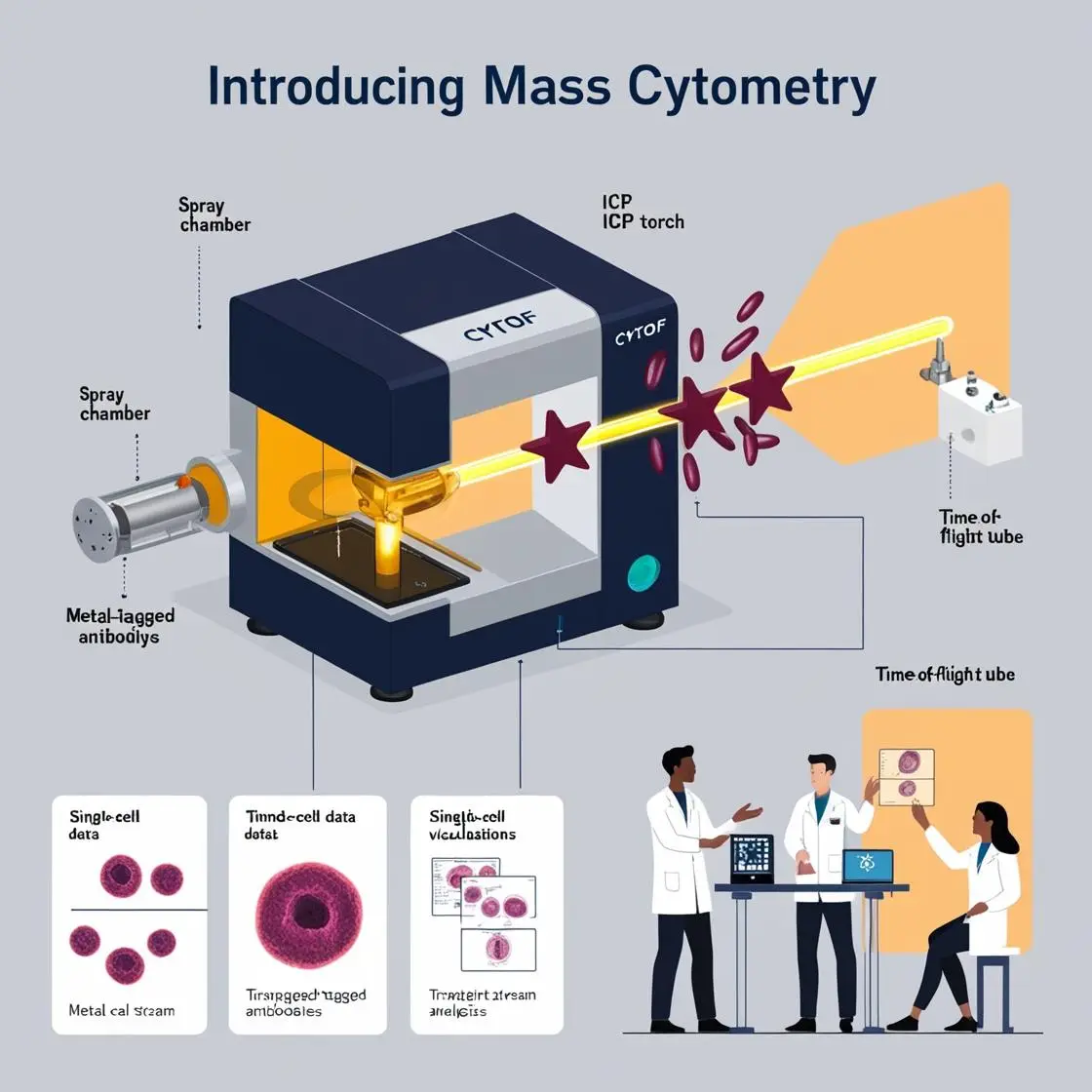
In the realm of high-dimensional data analysis, dimensionality reduction techniques are the magician’s tricks that allow us to glimpse the hidden structure of complex datasets. Let’s explore these fascinating methods that transform the incomprehensible into the visualizable.
The Unsung Hero of Data Visualization
Before we dive into the techniques, let’s talk about an unsung hero of data science: Laurens van der Maaten. A brilliant mind who emerged from the halls of TU Delft in the Netherlands, van der Maaten would go on to revolutionize the field of data visualization.
In 2008, as a PhD student, van der Maaten, along with his supervisor Geoffrey Hinton, published a paper in the Journal of Machine Learning Research. At the time, this journal was relatively unknown, with an impact factor of around 5. The paper, titled “Visualizing Data using t-SNE,” might have seemed like just another academic publication. Little did anyone know that this humble paper would go on to become one of the most influential works in data science.
As of 2024, this paper has been cited over 45,000 times, a staggering number that places it among the most cited papers in the field of computer science. Van der Maaten’s work on t-SNE (t-Distributed Stochastic Neighbor Embedding) has become ubiquitous in data analysis, extending far beyond its original domain.
Today, van der Maaten works at Meta (formerly Facebook), where his expertise in dimensionality reduction and machine learning continues to shape the digital world we interact with daily. His journey from a PhD student at TU Delft to a leading figure in one of the world’s largest tech companies is a testament to the power of innovative ideas.
Restricted content
You must be logged in and have a valid subscription to see this content. Please visit our subscription page for more info. If you are already a VIP member, be sure you are logged in with the same email address you made your purchase.
The impact of these dimensionality reduction techniques extends far beyond academic circles. Here are a few examples of where you might encounter them in everyday life:
- Spotify’s music recommendations: t-SNE helps group similar songs together, powering those eerily accurate playlists.
- Face recognition in your phone’s photo app: Dimensionality reduction techniques help group similar faces, making it easier to find photos of specific people.
- Netflix’s movie suggestions: These algorithms help Netflix understand the complex relationships between different films and viewer preferences.
- Medical imaging: In radiology, these techniques can help identify patterns in scans that might indicate disease.
- Fraud detection in banking: By reducing the dimensionality of transaction data, banks can more easily spot unusual patterns that might indicate fraud.
As we close this exploration of dimensionality reduction techniques, we find ourselves standing at the intersection of mathematics, computer science, and biology. From PCA to t-SNE to UMAP, these methods have transformed our ability to understand and visualize complex data, serving as the unsung heroes working behind the scenes in many of the technologies we use every day.
In our journey through the ever-expanding universe of high-dimensional data, these techniques are our cosmic lenses, allowing us to perceive patterns and structures that would otherwise remain hidden in the vastness of data space. They are the bridge between the intricate complexity of biological systems and our limited human perception, enabling us to grasp insights that were once beyond our reach.
The stories of Laurens van der Maaten and Etienne Becht remind us that scientific revolutions often begin with a single paper, a novel application, or a fresh perspective. Their contributions underscore the power of interdisciplinary thinking and the profound impact that can arise from applying existing tools to new domains.
So, the next time you generate a t-SNE plot or explore your cellular data through the lens of UMAP, take a moment to marvel at the elegant algorithms that are helping you navigate your cellular universe. Remember that you’re not just analyzing data – you’re peering through windows crafted by brilliant minds, glimpsing the intricate ballet of biology in ways that were unimaginable just a few decades ago.
In the grand tapestry of scientific discovery, dimensionality reduction techniques are the threads that weave together disparate data points into coherent, illuminating patterns. As we continue to push the boundaries of high-dimensional analysis, who knows what new insights await us in the depths of our data? The journey of discovery continues, one dimension at a time.
When I first encountered tSNE, UMAP, and HSNE, it felt like being dropped into a bowl of alphabet soup. These dimensionality reduction techniques swirled around my brain, each promising to be the cartographer of my high-dimensional data world. At first, I simplified things to the point of absurdity. UMAP became the cool new kid on the block, tSNE's hip younger sibling. HSNE? Oh, that was just tSNE with a superiority complex and a penchant for big data. I met the brilliant minds behind these algorithms at conferences, including Etienne Becht in Breckenridge. But let's be honest - the pristine slopes of Colorado made a more lasting impression than any scientific discussion. Who can focus on data points when there's fresh powder calling? In the end, like choosing a favorite ski run, we all develop our preferences in dimensionality reduction. Just remember, whether you're navigating data clusters or black diamond trails, it's all about finding your perfect slope.
Guillaume Beyrend